Determinando as BDRs Mais Líquidas do Ibovespa Utilizando Python
No artigo de hoje avaliaremos a liquidez das BDRs listadas na bolsa de valores brasileira, a fim de determinar quais são as mais negociadas. Nossa análise será feita a partir do cáculo de uma média móvel (21 dias) do volume de negociações.
Antes de partirmos para o código, vamos entender um pouco sobre esse tipo de ação.
O que são as BDRs?
Uma ação BDR, do inglês Brazilian Depositary Receipt, nada mais é do que um certificado (ou recibo) que representa uma ação de uma empresa estrangeira no mercado nacional. Esses certificados são emitidos por instituições financeiras, chamadas de custodiantes, que são os verdadeiros sócios da empresa estrangeira. Existem também as instituições depositárias, que são responsáveis por administrar todo esse sistema e emitir tais recibos. O investidor final, por sua vez, toma posse desses papéis através da compra desses títulos representativos - as BDRs. Você pode ler mais sobre esse tipo de ação no site da B3.
Existem mais de 600 BDRs disponíveis na bolsa e para obter essa lista de maneira rápida e prática, faremos o web scraping dessa tabela disponibilizada no site do InvestNews.
Portanto, para fins didáticos, o post será dividido em 3 passos:
1. Web scraping da lista de BDRs listadas na B3;
2. Inserir os dados obtidos no passo anterior ao banco de dados (passo opcional para quem está acompanhando nossa série de artigos sobre banco de dados);
3. Determinar quais são as BDRs mais negociadas na bolsa.
1. Web scraping da lista de BDRs listadas na B3
Como de praxe, começaremos o nosso código importando as bibliotecas necessárias.
Todas as bibliotecas abaixo já foram utilizadas em artigos anteriores, com exceção da request, que utilizaremos para fazer a requisição HTTP da tabela mencionada acima.
# %%capture means we suppress the output
%%capture
import pandas as pd
import numpy as np
# Data visualiation library
import matplotlib.pyplot as plt
# Library to connect and convert python to sql
from sqlalchemy import create_engine
!pip install psycopg2-binary
import psycopg2
# Library to manipulate directories
import os
# Library to get stock data from Yahoo! Finance
!pip install -q yfinance
import yfinance as yf
# HTTP library
import requestsUtilizaremos a função requests.get() para fazer a requisição da url em questão e o atributo .text, para ler o html em um texto. Este último, por sua vez, será parseado em um dataframe através da função pd.read_html do pandas. Para entender mais sobre os métodos e atributos da biblioteca request, leia este Guia de Início Rápido.
O header do dataframe, ou seja, as colunas serão os valores da primeira linha da tabela e, como o post apresenta mais de uma tabela, selecionaremos apenas a primeira delas.
url = "https://investnews.com.br/financas/veja-a-lista-completa-dos-bdrs-disponiveis-para-pessoas-fisicas-na-b3/"
r = requests.get(url)
html = r.text
df = pd.read_html(html, header=0)[0]
df.head()| EMPRESA | CÓDIGO | SETOR | PAÍS DE ORIGEM | |
|---|---|---|---|---|
| 0 | 3M | MMMC34 | Indústria diversificada | EUA |
| 1 | AB INBEV | ABUD34 | Bebidas | Bélgica |
| 2 | ABB LTD | A1BB34 | Industrial | Switzerland |
| 3 | ABBOTT | ABTT34 | Farmacêuticos | EUA |
| 4 | ABBVIE | ABBV34 | Medicamentos e Outros Produtos | EUA |
Como estamos lidando com um número de dados relativamente grande (673 empresas), vamos checar algumas informações importantes como o ticker, por exemplo, utilizado para baixar os dados de uma ativo.
O ticker das BDRs geralmente apresentam o sufixo 34 (menos frequentemente 35). Vamos checar essa informação através da função str.endswith do pandas. Para facilitar, vamos utilizar um filtro (filter) que nos mostre apenas as linhas em que os valores da coluna CÓDIGO não (representado por ~) terminam em 34.
filter = ~(df["CÓDIGO"].str.endswith('34'))
df[filter]| EMPRESA | CÓDIGO | SETOR | PAÍS DE ORIGEM | |
|---|---|---|---|---|
| 29 | ALPHABET | GOGL35 | Tecnologia | EUA |
| 187 | DISCOVERY INC | DCVY35 | Telecomunicações | EUA |
| 222 | EXELON CORP | E1XC34monde | Energia | EUA |
| 305 | ING GROEP | INGG3 | Instituição Financeira | Holanda |
| 353 | LIBERTY GLOBAL PLC | L1BT35 | Comunicação | Reino Unido |
| 355 | LIBERTY MEDIA CORPORATION | LSXM35 | Comunicação | EUA |
| 416 | NEWS CORPORATION | N1WS35 | Publicidade | EUA |
| 497 | ROYAL DUTCH SHELL PLC | RDSA35 | Energia | Holanda |
Podemos observar dois códigos que estão errados: E1XC34monde, que deveria ser somente E1XC34, e INGG3, que deveria ser INGG34.
Vamos corrigi-los utilizando novamente um filtro, dessa vez buscando pelos valores incorretos e substituindo-os pelo valor correto.
filter = df["CÓDIGO"] == "E1XC34monde"
df["CÓDIGO"][filter] = "E1XC34"
df[filter]| EMPRESA | CÓDIGO | SETOR | PAÍS DE ORIGEM | |
|---|---|---|---|---|
| 222 | EXELON CORP | E1XC34 | Energia | EUA |
filter = df["CÓDIGO"] == "INGG3"
df["CÓDIGO"][filter] = "INGG34"
df[filter]| EMPRESA | CÓDIGO | SETOR | PAÍS DE ORIGEM | |
|---|---|---|---|---|
| 305 | ING GROEP | INGG34 | Instituição Financeira | Holanda |
Pronto! Acabamos de fazer o que chamamos de data cleasing no âmbito do Data Science.
O próximo passo será voltado para quem está acompanhando (ou deseja acompanhar) nossa série sobre como montar um banco de dados de ações, que já conta com dois artigos práticos e didáticos:
- Como Criar Seu Próprio Banco de Dados de Ações Utilizando Python e SQL;
- Criando uma Base de Dados de Preços de Ativos Utilizando Python.
Se você está apenas interessado em saber quais são as BDRs mais negociadas na bolsa, pode pular para o terceiro e último passo!
2. Inserindo as BDRs no banco de dados
Antes de qualquer coisa, precisamos estabelecer uma conexão com o banco de dados através da função create_engine.
# Replace the variables below with your own data
user_name = 'postgres'
password = 'mypwd'
host = 'localhost'
port = 5432
db_name = 'quantbrasil'
DB_ADDRESS = "postgresql://{}:{}@{}:{}/{}".format(user_name, password, host, port, db_name)
engine = create_engine(DB_ADDRESS)O próximo passo é organizar as informações que serão inseridas na tabela asset: o nome das empresas (coluna EMPRESA) e o seu ticker (coluna CÓDIGO). Além disso, criaremos uma nova coluna YF_CÓDIGO, que conterá os tickers utilizados pela biblioteca do Yahoo Finance: ticker acrescido do sufixo .SA.
bdr = df.loc[:,["EMPRESA", "CÓDIGO"]].copy()
bdr["YF_CÓDIGO"] = bdr["CÓDIGO"] + ".SA"
bdr
| EMPRESA | CÓDIGO | YF_CÓDIGO | |
|---|---|---|---|
| 0 | 3M | MMMC34 | MMMC34.SA |
| 1 | AB INBEV | ABUD34 | ABUD34.SA |
| 2 | ABB LTD | A1BB34 | A1BB34.SA |
| 3 | ABBOTT | ABTT34 | ABTT34.SA |
| 4 | ABBVIE | ABBV34 | ABBV34.SA |
| ... | ... | ... | ... |
| 668 | ORACLE | ORCL34 | ORCL34.SA |
| 669 | RAYTHEON TECH | RYTT34 | RYTT34.SA |
| 670 | SCHLUMBERGER | SLBG34 | SLBG34.SA |
| 671 | TIFFANY | TIFF34 | TIFF34.SA |
| 672 | US BANCORP | USBC34 | USBC34.SA |
673 rows × 3 columns
Agora podemos escrever e executar a query que irá inserir os dados acima:
insert_initial = """
INSERT INTO asset (name, symbol, yf_symbol)
VALUES
"""
values = ",".join([
"('{}', '{}', '{}')"
.format(row["EMPRESA"], row["CÓDIGO"], row["YF_CÓDIGO"])
for symbol, row in bdr.iterrows()
])
insert_end = """
ON CONFLICT (symbol) DO UPDATE
SET
name = EXCLUDED.name,
symbol = EXCLUDED.symbol,
yf_symbol = EXCLUDED.yf_symbol;
"""
query = insert_initial + values + insert_end
engine.execute(query)<sqlalchemy.engine.result.ResultProxy at 0x11dc9c7c0>Com a tabela asset devidamente populada, vamos agora criar o portfólio BDR na tabela portfolio através de uma segunda query de inserção:
insert_portfolio_query = """
INSERT INTO portfolio (name)
VALUES ('BDR')
ON CONFLICT (name)
DO UPDATE SET name = EXCLUDED.name;
"""
engine.execute(insert_portfolio_query)<sqlalchemy.engine.result.ResultProxy at 0x11d964430>Finalmente, o último passo é popular a tabela asset_portfolio com o id de cada ativo recém inserido e o id do respectivo portfólio.
Para isso, importaremos através da função pd.read_sql os ids desses ativos (lembrando que SQL só aceita esses valores em tupla - tuple(df["CÓDIGO"])) e do portfólio recém adicionados às tabelas asset e portfolio respectivamente.
# Importing asset and portfolio ids from PostgreSQL
symbol_tuple = tuple(bdr["CÓDIGO"])
asset_portfolio_df = pd.read_sql(f"SELECT id FROM asset WHERE symbol IN {symbol_tuple};", engine)
asset_portfolio_df.columns = ["asset_id"]
bdr_portfolio_id = pd.read_sql("SELECT id FROM portfolio WHERE name='BDR';", engine)
asset_portfolio_df["portfolio_id"] = int(bdr_portfolio_id["id"])Com o dataframe asset_portfolio_df contendo as colunas com os respectivos ids (asset_id e portfolio_id), podemos escrever e executar a query que irá inserir esses dados na tabela asset_portfolio:
# Writing the SQL query to populate asset_portfolio table
insert_init = """
INSERT INTO asset_portfolio (asset_id, portfolio_id)
VALUES
"""
values = ",".join(["('{}', '{}')"
.format(int(row["asset_id"]), int(row["portfolio_id"]))
for asset_id, row in asset_portfolio_df.iterrows()
])
insert_end = """
ON CONFLICT (asset_id, portfolio_id) DO UPDATE
SET
asset_id = EXCLUDED.asset_id,
portfolio_id = EXCLUDED.portfolio_id
"""
query = insert_init + values + insert_end
engine.execute(query)<sqlalchemy.engine.result.ResultProxy at 0x11dcdd940>Pronto. Com as informações salvas no nosso banco de dados podemos finalmente determinar as BDRs mais líquidas.
3. Determinando quais são as BDRs mais negociadas na bolsa
Para determinar quais são as BDRs de maior liquidez, temos primeiro que baixar seus volumes através da biblioteca do Yahoo Finance. Vale ressaltar que, nesse caso, o volume demonstra o número de ações negociadas no período.
Os tickers serão os valores da coluna YF_CÓDIGO no formato de lista. Baixaremos os dados de uma janela de 2 meses (2mo).
tickers = list(bdr["YF_CÓDIGO"])
df = yf.download(tickers, period='2mo').copy()['Volume'][*********************100%***********************] 673 of 673 completed
6 Failed downloads:
- C1HL34.SA: No data found, symbol may be delisted
- TIFF34.SA: No data found, symbol may be delisted
- V1AR34.SA: No data found, symbol may be delisted
- C1EO34.SA: No data found, symbol may be delisted
- C1XO34.SA: No data found, symbol may be delisted
- U1NL34.SA: No data found, symbol may be delisted
Veja que recebemos um erro de falha ao tentar baixar os dados dos tickers acima, provavelmente porque a biblioteca não contém essas informações. Como são apenas 6 empresas dentre 673, vamos excluí-las do dataframe (através da função drop) e prosseguir com nossa análise.
df.drop(columns=["C1HL34.SA", "TIFF34.SA", "V1AR34.SA", "C1EO34.SA", "C1XO34.SA", "U1NL34.SA"], inplace=True)Como vamos trabalhar com a média de uma janela de tempo relativamente pequena, vamos verificar a quantidade de valores NaN que nosso dataframe possui, através das função combinadas: isnull, any e sum.
df.isnull().any().sum()520Repare que nós possuimos um número considerável de valores NaN (520). Vamos, portanto, interpolar esses valores faltantes de cada coluna, de modo a ter dados suficientes para o cálculo da média móvel.
Faremos isso através da função interpolate do pandas.
df.interpolate(inplace=True)A fim de calcular a média móvel de 21 dias para cada um dos ativos, vamos iterar sobre cada coluna do nosso dataframe. Adicionaremos essas informações a um novo dataframe: mm21.
mm21 = pd.DataFrame()
for column in df.columns:
mm21[column] = df[column].rolling(21).mean()
mm21 = mm21[20:]
mm21.head()| A1AP34.SA | A1BB34.SA | A1BM34.SA | A1CR34.SA | A1DI34.SA | A1DM34.SA | A1EE34.SA | A1EG34.SA | A1EN34.SA | A1EP34.SA | ... | X1YL34.SA | XRAY34.SA | XRXB34.SA | YUMR34.SA | Z1BH34.SA | Z1BR34.SA | Z1IO34.SA | Z1OM34.SA | Z1TO34.SA | Z1TS34.SA | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Date | |||||||||||||||||||||
| 2021-04-12 | 5489.666667 | 84.714286 | 37.666667 | 5.523810 | 1.142857 | 4.809524 | 0.619048 | 69.476190 | 5.904762 | 28.571429 | ... | 35.047619 | 0.095238 | 4.285714 | 0.000000 | 0.619048 | 118.428571 | 0.809524 | 19884.666667 | 241.714286 | 2163.047619 |
| 2021-04-13 | 5721.238095 | 85.047619 | 36.000000 | 5.809524 | 1.571429 | 2.190476 | 0.809524 | 68.809524 | 5.904762 | 28.523810 | ... | 35.047619 | 0.095238 | 4.285714 | 0.000000 | 0.476190 | 113.238095 | 0.809524 | 20475.571429 | 242.428571 | 2256.904762 |
| 2021-04-14 | 3199.000000 | 84.523810 | 35.904762 | 5.904762 | 1.523810 | 2.571429 | 0.809524 | 67.619048 | 8.761905 | 28.523810 | ... | 29.761905 | 0.095238 | 4.523810 | 0.000000 | 0.476190 | 108.476190 | 0.809524 | 20994.380952 | 243.238095 | 1296.619048 |
| 2021-04-15 | 3538.285714 | 86.809524 | 35.904762 | 5.238095 | 1.523810 | 2.523810 | 0.809524 | 66.476190 | 8.761905 | 28.285714 | ... | 29.761905 | 0.095238 | 4.619048 | 0.333333 | 0.476190 | 108.476190 | 0.666667 | 21836.190476 | 245.809524 | 1296.428571 |
| 2021-04-16 | 3649.047619 | 85.761905 | 35.904762 | 9.238095 | 1.523810 | 2.523810 | 0.809524 | 66.523810 | 8.761905 | 4.333333 | ... | 29.952381 | 0.095238 | 4.666667 | 0.333333 | 0.476190 | 99.238095 | 0.666667 | 22511.428571 | 204.809524 | 1163.380952 |
5 rows × 667 columns
O próximo passo é selecionar os valores da última linha (que são os valores atuais) e ordená-los através da função sort_values em ordem decrescente (ascending=False).
sorted_mm21 = mm21.iloc[-1].sort_values(ascending=False)
sorted_mm21
MELI34.SA 800630.619048 TSLA34.SA 594247.619048 BABA34.SA 194046.809524 AAPL34.SA 177718.190476 MSFT34.SA 170175.523810 ... P1EG34.SA 0.000000 T1LK34.SA 0.000000 B1IL34.SA NaN L1MN34.SA NaN L1YG34.SA NaN Name: 2021-05-12 00:00:00, Length: 667, dtype: float64Pronto! Agora vamos plotar as 15 BDRs (top_15_bdr) mais líquidas em um gráfico de barras horizontais (barh) através da função plot do matplotlib.
fig = plt.figure(figsize=(18,12))
top_15_bdr = sorted_mm21[:15]
ax = top_15_bdr.plot(kind='barh')
ax.invert_yaxis()
ax.set_title("As 15 BDRs de Mais Negociadas da Bolsa de Valores Brasileira")Text(0.5, 1.0, 'As 15 BDRs de Mais Negociadas da Bolsa de Valores Brasileira')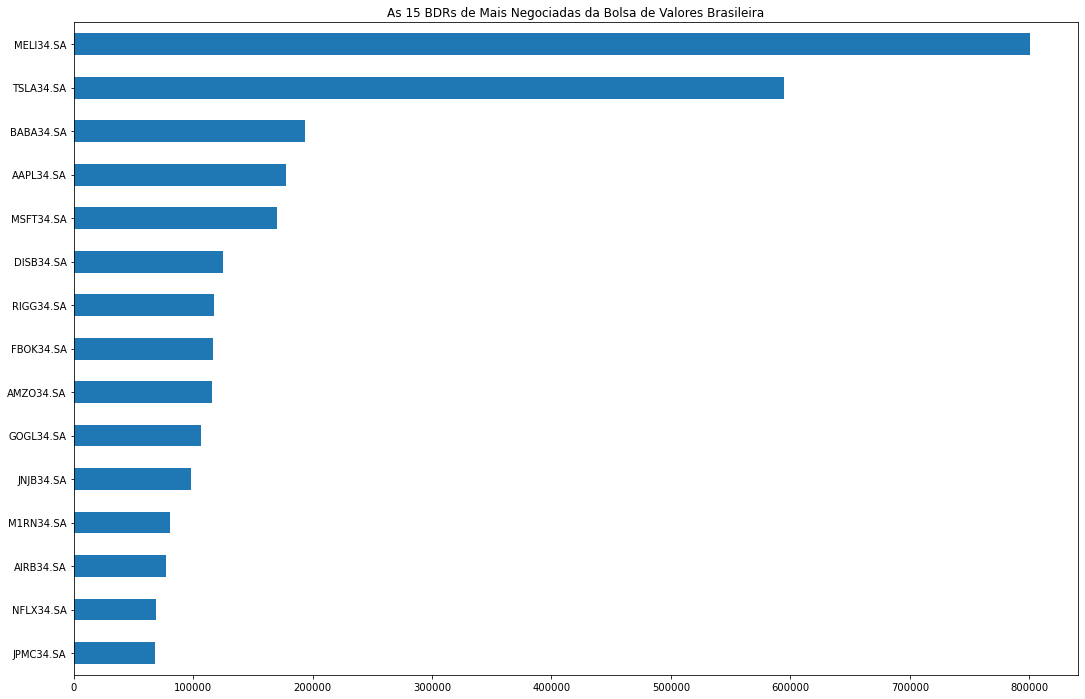
Como podemos observar pelo gráfico acima, as duas primeiras empresas - Mercado Livre (MELI34) e Tesla (TSLA34) - apresentam mais da metade do volume total das 15 BDRs mais negociadas. A BDR mais líquida negociou seis vezes mais que NFLX34 (Netflix), que ocupa a 10ª posição. Isso nos mostra a imensa discrepância que há entre as top 10 BDRs mais negociadas na bolsa.
A fim de termos um valor de referência e assim sermos capazes de julgar a liquidez de uma BDR, vamos avaliar a liquidez de mais três ativos:
- Um ativo do índice de alta liquidez:
PETR4; - Um ativo do índice de menor liquidez:
EGIE3; - Um ativo qualquer que não faça parte do índice:
SOMA3.
df = yf.download(["PETR4.SA", "EGIE3.SA", "SOMA3.SA"], period='2mo').copy()["Volume"]
df.interpolate(inplace=True)
mm21 = pd.DataFrame()
for column in df.columns:
mm21[column] = df[column].rolling(21).mean()[*********************100%***********************] 3 of 3 completed
Com as médias móveis calculadas, basta juntar a última linha (mm21.iloc[-1]]) com as duas BDRs mais líquidas (top_15_bdr[:2]), ordená-las e enfim, plotá-las novamente em um gráfico de barras horizontais.
liquidity_analysis = pd.concat([top_15_bdr[:2], mm21.iloc[-1]])
liquidity_analysis = liquidity_analysis.sort_values(ascending=False)
fig = plt.figure(figsize=(18,12))
ax = liquidity_analysis.plot(kind='barh')
ax.invert_yaxis()
Conclusão
Vemos logo de cara que a diferença entre a BDR e o ativo do índice mais negociados (MELI34 e PETR4, respectivamente) é gritante!
Mesmo comparado a um dos ativos menos negociados do índice (EGIE3) ou ainda um ativo que não faça parte do índice (SOMA3), a BDR mais líquida não chega a obter metade do volume (e ainda não estamos considerando o lote fracionário).
Essa discrepância nos leva a crer que ainda há espaço para que esse tipo de ação cresça e aumente a liquidez no longo prazo. Entretanto, é importante ressaltar que trades em timeframes mais curtos apresentam um alto risco, tendo em vista a baixa liquidez desses títulos e, consequentemente, a volatilidade dos seus preços.
Se esse tipo de conteúdo te interessa, não deixa de se inscrever na nossa Newsletter logo abaixo e participar do nosso grupo no Telegram!
Inscreva-se no canal do QuantBrasil!
Acompanhe novidades sobre a plataforma, vídeos sobre finanças quantitativas, tutoriais sobre programação e Inteligência Artificial!