Como Criar Seu Próprio Banco de Dados de Ações Utilizando Python e SQL
O post de hoje será o primeiro de uma série de artigos sobre como criar um banco de dados de ações do zero, utilizando Python e SQL.
Se você é um leitor assíduo da QuantBrasil, já sabe que atualmente nós baixamos os dados necessários para nossas análises através da biblioteca do Yahoo Finance.
Além disso, em alguns casos, como no artigo Comparando os Resultados da Estratégia de IFR2 nos Ativos do Ibovespa, nós extraímos as ações que compõem a carteira do Ibovespa diretamente do site da B3.
Esse método de raspagem de dados da web (web scraping) apresenta algumas desvantagens, uma vez que ficamos dependentes de que o site em questão tenha dados estruturados, navegação estável, rápida e livre de bugs. Ao criar seu próprio banco de dados, conseguimos mitigar esses problemas.
O que é um Banco de Dados?
De forma simples, um banco de dados é um sistema para armazenamento e gerenciamento de informações. Existem diferentes modelos de implementação. No nosso caso, utilizaremos o modelo relacional, onde as tabelas se relacionam através de chaves.
Podemos simplificar a criação de um banco de dados em duas tarefas principais:
- Modelagem de dados, que compreende a organização estrutural e lógica das tabelas;
- Inserção dos dados, ou seja, popular as tabelas modeladas no passo anterior.
A linguagem utilizada para esse tipo de modelo é a SQL (Structured Query Language), e o banco de dados escolhido será o PostgreSQL.
O que é SQL?
SQL é uma linguagem que nos permite acessar, consultar e modificar os dados estruturais através das chamadas queries (consultas). Exemplos de comandos para formulação dessas queries são: CREATE, ALTER, DROP, SELECT, INSERT, DELETE e UPDATE.
Ao longo do post, veremos alguns desses comandos na prática.
1. Modelagem de dados
Dividiremos essa primeira etapa em 4 passos:
- Identificar as tabelas necessárias;
- Determinar as colunas e os tipos de dados para cada tabela;
- Definir as restrições e os relacionamentos entre as tabelas;
- Escrever as queries com todas as informações acima.
1.1 Identificando as tabelas necessárias
O primeiro objetivo do nosso banco de dados será armazenar quais ativos pertencem ao Ibovespa. Portanto, precisaremos de duas entidades:
asset, que armazenará as informações relacionadas aos ativos;portfolio, que armazerá quais ativos pertencem a uma determinada carteira.
Para garantir a unicidade dos dados, é necessário criar uma terceira entidade associativa chamada asset_portfolio. Explicar detalhes de modelagem está fora do escopo desse artigo, mas recomendamos a seguinte leitura caso deseje se aprofundar no assunto.
Note que o relacionamento entre asset e asset_porfolio é de 1:n, isto é, nós podemos ter n registros de asset em asset_portfolio (uma vez que um mesmo ativo pode compor mais de uma carteira) mas apenas uma combinação de asset e portfolio em asset_portfolio (já que um ativo só pode aparecer no máximo uma vez em cada carteira). O relacionamento entre portfolio e asset_portfolio é análogo.
O diagrama a seguir representa o relacionamento descrito:
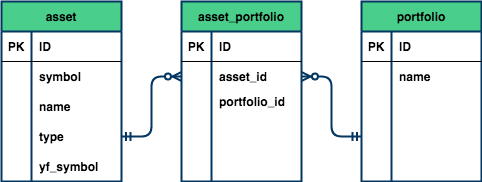
Para mais detalhes sobre a cardinalidade de um banco de dados recomendamos a leitura do desse artigo.
1.2 Determinando as colunas e os tipos de dados
A tabela asset terá as seguintes colunas:
id: identificador único do registro;symbol: código do ativo;name: nome da empresa;type: tipo do ativo;yf_symbol: código do ativo utilizado pela biblioteca do Yahoo Finance.
Já a tabela portfolio, por sua vez, apresentará apenas duas colunas:
id;name: nome da carteira (por exemplo,IBOV).
Finalmente, para asset_portfolio:
id;asset_id: identificador único do ativo;portfolio_id: identificador único do portfólio.
Além disso, nós temos que identificar o tipo de dado de cada coluna. Utilizaremos basicamente 3:
BIGSERIAL: número inteiro sequencial utilizado para os identificadores;INTEGER: números inteiros;VARCHAR: texto de tamanho variável.
Para entender os diferentes tipos de dados, sugiro a leitura da documentação do PostgreSQL.
1.3 Definindo as restrições e os relacionamentos
As restrições em SQL nos permitem ter um maior controle sobre os dados de cada tabela e garantir a integridade dos mesmos.
As restrições que iremos utilizar são:
- chaves: primária (Primary Key), estrangeira (Foreign Key) e única (Unique);
- not null.
A chave primária é responsável por automaticamente criar um índice único, além de permitir o acesso rápido aos dados quando a mesma é utilizada em consultas. Por conta disso, elas geralmente são definidas na coluna id.
Já a chave estrangeira é responsável por estabelecer as relações entre os dados de diferentes tabelas, criando um link entre elas. Esse link é criado quando a coluna de identificação da chave primária de uma tabela é referenciada em outra.
Finalmente, as chaves primária e única garantem a unicidade de informações, mas somente a chave primária pode ser utilizada como chave estrangeira. Portanto, utilizaremos a chave única na coluna symbol, uma vez que só podemos ter uma linha para cada ativo na tabela asset e não estamos referenciando symbol em nenhuma outra tabela.
1.4 Escrevendo as queries
Para efetivamente criar as tabelas e os relacionamentos acima, você precisa ter o psql instalado localmente e um banco de dados criado.
As queries a seguir compreendem tudo que foi descrito nos tópicos anteriores:
'''
The following queries need to be run in your own database:
CREATE TABLE asset (
id BIGSERIAL PRIMARY KEY,
symbol VARCHAR (10) NOT NULL UNIQUE,
name VARCHAR (100) NOT NULL,
type VARCHAR (10),
yf_symbol VARCHAR (10) NOT NULL
);
CREATE TABLE portfolio (
id BIGSERIAL PRIMARY KEY,
name VARCHAR (100) NOT NULL UNIQUE
);
CREATE TABLE asset_portfolio (
id BIGSERIAL PRIMARY KEY,
asset_id INTEGER NOT NULL REFERENCES asset(id),
portfolio_id INTEGER NOT NULL REFERENCES portfolio(id),
UNIQUE (asset_id, portfolio_id)
);
'''
2. Inserindo os dados
Agora que as tabelas e seus relacionamentos já foram criadas, o próximo passo é populá-las com dados reais.
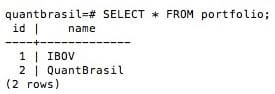
Populando a tabela portfolio
No nosso exemplo, portfolio terá apenas dois registros: Ibovespa (com todos os ativos do IBOV) e QuantBrasil (com ativos aleatoriamente selecionados).
Para inserir dados em uma tabela já criada, basta utilizar o comando INSERT INTO no seguinte formato:
'''
Run the following query in your own database to create two portfolios:
INSERT INTO portfolio (name) VALUES ('IBOV'), ('QuantBrasil');
'''
Para visualizar como ficou a tabela, basta utilizar o comando SELECT.
O resultado da query SELECT * FROM portfolio será o seguinte (asterisco em SQL compreende todas as linhas e colunas de uma tabela):
Populando a tabela asset
Para a tabela asset, nós iremos extrair as colunas Código, Ação e Tipo, da seguinte tabela no site da B3. Para isso, precisamos primeiro importar e instalar as bibliotecas necessárias.
Utilizaremos duas novas bibliotecas: SQLAlchemy e psycopg2. Elas serão utilizada para converter as instruções Python em SQL e enviá-las ao banco de dados.
%%capture
import pandas as pd
import numpy as np
!pip install yfinance
import yfinance as yf
import sqlalchemy
from sqlalchemy import create_engine
!pip install psycopg2-binary
import psycopg2A função a seguir é similar à criada no post Comparando os Resultados da Estratégia de IFR2 nos Ativos do Ibovespa, com a diferença de que vamos selecionar as 3 primeiras colunas do dataframe e renomeá-las para coincidir com os nomes do nosso modelo de dados.
def get_ibov_info():
url = "http://bvmf.bmfbovespa.com.br/indices/ResumoCarteiraTeorica.aspx?Indice=IBOV&idioma=pt-br"
html = pd.read_html(url, decimal=",", thousands=".")[0][:-1]
df = html.copy()[['Código', 'Ação', 'Tipo']]
df.rename(columns={
'Código': 'symbol',
'Ação': 'name',
'Tipo': 'type'
}, inplace=True)
return df
asset = get_ibov_info()
asset
| symbol | name | type | |
|---|---|---|---|
| 0 | ABEV3 | AMBEV S/A | ON |
| 1 | ASAI3 | ASSAI | ON NM |
| 2 | AZUL4 | AZUL | PN N2 |
| 3 | B3SA3 | B3 | ON NM |
| 4 | BBAS3 | BRASIL | ON ERJ NM |
| ... | ... | ... | ... |
| 77 | VALE3 | VALE | ON NM |
| 78 | VIVT3 | TELEF BRASIL | ON EJ |
| 79 | VVAR3 | VIAVAREJO | ON NM |
| 80 | WEGE3 | WEG | ON ED NM |
| 81 | YDUQ3 | YDUQS PART | ON NM |
82 rows × 3 columns
A única coluna restante na tabela asset é yf_symbol, ou seja, o ticker utilizando para identificar o ativo na API do Yahoo Finance. No nosso exemplo, faremos isso simplesmente acrescentando o sufixo '.SA' à coluna symbol.
asset['yf_symbol'] = asset['symbol'] + '.SA'
asset
| symbol | name | type | yf_symbol | |
|---|---|---|---|---|
| 0 | ABEV3 | AMBEV S/A | ON | ABEV3.SA |
| 1 | ASAI3 | ASSAI | ON NM | ASAI3.SA |
| 2 | AZUL4 | AZUL | PN N2 | AZUL4.SA |
| 3 | B3SA3 | B3 | ON NM | B3SA3.SA |
| 4 | BBAS3 | BRASIL | ON ERJ NM | BBAS3.SA |
| ... | ... | ... | ... | ... |
| 77 | VALE3 | VALE | ON NM | VALE3.SA |
| 78 | VIVT3 | TELEF BRASIL | ON EJ | VIVT3.SA |
| 79 | VVAR3 | VIAVAREJO | ON NM | VVAR3.SA |
| 80 | WEGE3 | WEG | ON ED NM | WEGE3.SA |
| 81 | YDUQ3 | YDUQS PART | ON NM | YDUQ3.SA |
82 rows × 4 columns
Pronto! Temos nossa tabela asset em formato de DataFrame. O próximo passo é escrever uma query para transformá-la em SQL.
Faremos isso a partir do conceito de upsert (update + insert), onde um dado é inserido na tabela se ele não existir, ou atualizado caso contrário.
Os comandos utilizados para fazer um upsert são INSERT, ON CONFLICT e UPDATE. Para fins didáticos, vamos dividir a query em 3 partes:
insert_initial: início da query caracterizado pelo comandoINSERT;values: valores que serão inseridos na tabela. Gerarmos esses valores dinamicamente através das seguintes funções:insert_end: final da query onde vamos determinar que, caso haja um conflito de valores já existentes, eles sejam excluídos e atualizados com os valores presentes na query.
insert_initial = """
INSERT INTO asset (symbol, name, type, yf_symbol)
VALUES
"""
values = ",".join([
"('{}', '{}', '{}', '{}')"
.format(row["symbol"], row["name"], row["type"], row["yf_symbol"])
for symbol, row in asset.iterrows()
])
insert_end = """
ON CONFLICT (symbol) DO UPDATE
SET
symbol = EXCLUDED.symbol,
name = EXCLUDED.name,
type = EXCLUDED.type,
yf_symbol = EXCLUDED.yf_symbol;
"""
query = insert_initial + values + insert_end
print(query) INSERT INTO asset (symbol, name, type, yf_symbol)
VALUES
('ABEV3', 'AMBEV S/A', 'ON', 'ABEV3.SA'),('ASAI3', 'ASSAI', 'ON NM', 'ASAI3.SA'),('AZUL4', 'AZUL', 'PN N2', 'AZUL4.SA'),('B3SA3', 'B3', 'ON NM', 'B3SA3.SA'),('BBAS3', 'BRASIL', 'ON ERJ NM', 'BBAS3.SA'),('BBDC3', 'BRADESCO', 'ON EJ N1', 'BBDC3.SA'),('BBDC4', 'BRADESCO', 'PN EJ N1', 'BBDC4.SA'),('BBSE3', 'BBSEGURIDADE', 'ON NM', 'BBSE3.SA'),('BEEF3', 'MINERVA', 'ON NM', 'BEEF3.SA'),('BPAC11', 'BTGP BANCO', 'UNT N2', 'BPAC11.SA'),('BRAP4', 'BRADESPAR', 'PN N1', 'BRAP4.SA'),('BRDT3', 'PETROBRAS BR', 'ON NM', 'BRDT3.SA'),('BRFS3', 'BRF SA', 'ON NM', 'BRFS3.SA'),('BRKM5', 'BRASKEM', 'PNA N1', 'BRKM5.SA'),('BRML3', 'BR MALLS PAR', 'ON NM', 'BRML3.SA'),('BTOW3', 'B2W DIGITAL', 'ON NM', 'BTOW3.SA'),('CCRO3', 'CCR SA', 'ON NM', 'CCRO3.SA'),('CIEL3', 'CIELO', 'ON NM', 'CIEL3.SA'),('CMIG4', 'CEMIG', 'PN N1', 'CMIG4.SA'),('COGN3', 'COGNA ON', 'ON NM', 'COGN3.SA'),('CPFE3', 'CPFL ENERGIA', 'ON NM', 'CPFE3.SA'),('CPLE6', 'COPEL', 'PNB N1', 'CPLE6.SA'),('CRFB3', 'CARREFOUR BR', 'ON NM', 'CRFB3.SA'),('CSAN3', 'COSAN', 'ON NM', 'CSAN3.SA'),('CSNA3', 'SID NACIONAL', 'ON', 'CSNA3.SA'),('CVCB3', 'CVC BRASIL', 'ON NM', 'CVCB3.SA'),('CYRE3', 'CYRELA REALT', 'ON NM', 'CYRE3.SA'),('ECOR3', 'ECORODOVIAS', 'ON NM', 'ECOR3.SA'),('EGIE3', 'ENGIE BRASIL', 'ON NM', 'EGIE3.SA'),('ELET3', 'ELETROBRAS', 'ON N1', 'ELET3.SA'),('ELET6', 'ELETROBRAS', 'PNB N1', 'ELET6.SA'),('EMBR3', 'EMBRAER', 'ON NM', 'EMBR3.SA'),('ENBR3', 'ENERGIAS BR', 'ON NM', 'ENBR3.SA'),('ENEV3', 'ENEVA', 'ON NM', 'ENEV3.SA'),('ENGI11', 'ENERGISA', 'UNT N2', 'ENGI11.SA'),('EQTL3', 'EQUATORIAL', 'ON NM', 'EQTL3.SA'),('EZTC3', 'EZTEC', 'ON NM', 'EZTC3.SA'),('FLRY3', 'FLEURY', 'ON NM', 'FLRY3.SA'),('GGBR4', 'GERDAU', 'PN N1', 'GGBR4.SA'),('GNDI3', 'INTERMEDICA', 'ON NM', 'GNDI3.SA'),('GOAU4', 'GERDAU MET', 'PN N1', 'GOAU4.SA'),('GOLL4', 'GOL', 'PN N2', 'GOLL4.SA'),('HAPV3', 'HAPVIDA', 'ON NM', 'HAPV3.SA'),('HGTX3', 'CIA HERING', 'ON NM', 'HGTX3.SA'),('HYPE3', 'HYPERA', 'ON NM', 'HYPE3.SA'),('IGTA3', 'IGUATEMI', 'ON NM', 'IGTA3.SA'),('IRBR3', 'IRBBRASIL RE', 'ON NM', 'IRBR3.SA'),('ITSA4', 'ITAUSA', 'PN ED N1', 'ITSA4.SA'),('ITUB4', 'ITAUUNIBANCO', 'PN EDJ N1', 'ITUB4.SA'),('JBSS3', 'JBS', 'ON NM', 'JBSS3.SA'),('JHSF3', 'JHSF PART', 'ON NM', 'JHSF3.SA'),('KLBN11', 'KLABIN S/A', 'UNT N2', 'KLBN11.SA'),('LAME4', 'LOJAS AMERIC', 'PN N1', 'LAME4.SA'),('LCAM3', 'LOCAMERICA', 'ON NM', 'LCAM3.SA'),('LREN3', 'LOJAS RENNER', 'ON NM', 'LREN3.SA'),('MGLU3', 'MAGAZ LUIZA', 'ON NM', 'MGLU3.SA'),('MRFG3', 'MARFRIG', 'ON NM', 'MRFG3.SA'),('MRVE3', 'MRV', 'ON NM', 'MRVE3.SA'),('MULT3', 'MULTIPLAN', 'ON N2', 'MULT3.SA'),('NTCO3', 'GRUPO NATURA', 'ON NM', 'NTCO3.SA'),('PCAR3', 'P.ACUCAR-CBD', 'ON EC NM', 'PCAR3.SA'),('PETR3', 'PETROBRAS', 'ON N2', 'PETR3.SA'),('PETR4', 'PETROBRAS', 'PN N2', 'PETR4.SA'),('PRIO3', 'PETRORIO', 'ON NM', 'PRIO3.SA'),('QUAL3', 'QUALICORP', 'ON NM', 'QUAL3.SA'),('RADL3', 'RAIADROGASIL', 'ON NM', 'RADL3.SA'),('RAIL3', 'RUMO S.A.', 'ON NM', 'RAIL3.SA'),('RENT3', 'LOCALIZA', 'ON NM', 'RENT3.SA'),('SANB11', 'SANTANDER BR', 'UNT', 'SANB11.SA'),('SBSP3', 'SABESP', 'ON NM', 'SBSP3.SA'),('SULA11', 'SUL AMERICA', 'UNT N2', 'SULA11.SA'),('SUZB3', 'SUZANO S.A.', 'ON NM', 'SUZB3.SA'),('TAEE11', 'TAESA', 'UNT N2', 'TAEE11.SA'),('TIMS3', 'TIM', 'ON NM', 'TIMS3.SA'),('TOTS3', 'TOTVS', 'ON NM', 'TOTS3.SA'),('UGPA3', 'ULTRAPAR', 'ON NM', 'UGPA3.SA'),('USIM5', 'USIMINAS', 'PNA N1', 'USIM5.SA'),('VALE3', 'VALE', 'ON NM', 'VALE3.SA'),('VIVT3', 'TELEF BRASIL', 'ON EJ', 'VIVT3.SA'),('VVAR3', 'VIAVAREJO', 'ON NM', 'VVAR3.SA'),('WEGE3', 'WEG', 'ON ED NM', 'WEGE3.SA'),('YDUQ3', 'YDUQS PART', 'ON NM', 'YDUQ3.SA')
ON CONFLICT (symbol) DO UPDATE
SET
symbol = EXCLUDED.symbol,
name = EXCLUDED.name,
type = EXCLUDED.type,
yf_symbol = EXCLUDED.yf_symbol;
Com a query escrita, temos que estabelecer uma conexão com o nosso banco de dados para enfim executá-la através da função execute.
No exemplo a seguir, estamos executando a query num usuário local (localhost) em um banco de dados chamado quantbrasil:
# switch DB_ADDRESS with your own
DB_ADDRESS = 'postgresql://postgres:@localhost/quantbrasil'
engine = create_engine(DB_ADDRESS)
engine.execute(query)<sqlalchemy.engine.result.ResultProxy at 0x11b77e490>Simples, não? Agora basta rodar o comando SELECT * FROM asset para visualizar toda a tabela (a imagem a seguir apresenta as 10 primeiras linhas).
Populando a tabela asset_portfolio
Para inserir os dados na tabela asset_portfolio, precisamos identificar os IDs de cada registro. A função pd.read_sql nos possibilita fazer isso de duas formas:
- diretamente pelo nome da tabela e especificando as colunas com o argumento
columns; - escrevendo a query diretamente (por exemplo:
SELECT id, symbol FROM asset;).
Em ambos os casos precisamos passar a conexão com o banco de dados (engine) como argumento:
# Make sure you have previously created engine
asset_sql = pd.read_sql('asset', engine, columns=['id','symbol'])
asset_sql
| id | symbol | |
|---|---|---|
| 0 | 1 | ABEV3 |
| 1 | 2 | ASAI3 |
| 2 | 3 | AZUL4 |
| 3 | 4 | B3SA3 |
| 4 | 5 | BBAS3 |
| ... | ... | ... |
| 77 | 78 | VALE3 |
| 78 | 79 | VIVT3 |
| 79 | 80 | VVAR3 |
| 80 | 81 | WEGE3 |
| 81 | 82 | YDUQ3 |
82 rows × 2 columns
Como nosso banco de dados só contém os ativos do IBOV, podemos transformar asset_sql no dataframe contendo os registros da carteira Ibovespa:
portfolio_ibov = asset_sql.copy()[["id"]]
portfolio_ibov.rename(columns={'id': 'asset_id'}, inplace=True)
portfolio_ibov
| asset_id | |
|---|---|
| 0 | 1 |
| 1 | 2 |
| 2 | 3 |
| 3 | 4 |
| 4 | 5 |
| ... | ... |
| 77 | 78 |
| 78 | 79 |
| 79 | 80 |
| 80 | 81 |
| 81 | 82 |
82 rows × 1 columns
O próximo passo é popular a coluna com os IDs das carteiras. Faremos isso de forma análoga, importando a tabela portfolio em um dataframe portfolio_sql.
portfolio_sql = pd.read_sql('portfolio', engine)
portfolio_sql
| id | name | |
|---|---|---|
| 0 | 1 | IBOV |
| 1 | 2 | QuantBrasil |
Como portfolio_ibov contém apenas os ativos que compõem o Ibovespa, vamos estabelecer uma condição para isolar o ID dessa carteira e designá-la à coluna portfolio_id.
portfolio_ibov["portfolio_id"] = int(portfolio_sql.loc[portfolio_sql["name"] == "IBOV", 'id'])
portfolio_ibov
| asset_id | portfolio_id | |
|---|---|---|
| 0 | 1 | 1 |
| 1 | 2 | 1 |
| 2 | 3 | 1 |
| 3 | 4 | 1 |
| 4 | 5 | 1 |
| ... | ... | ... |
| 77 | 78 | 1 |
| 78 | 79 | 1 |
| 79 | 80 | 1 |
| 80 | 81 | 1 |
| 81 | 82 | 1 |
82 rows × 2 columns
Prontinho! Nosso dataframe com os IDs relacionados à carteira do Ibovespa está pronto.
Agora vamos montar uma carteira do QuantBrasil com os seguintes ativos (aleatoriamente escolhidos): "ELET3", "JHSF3", "MGLU3", "PETR4" e "VALE3".
Faremos isso criando um novo dataframe: portfolio_quantbr.
condition = asset_sql["symbol"].isin(["ELET3", "JHSF3", "MGLU3", "PETR4", "VALE3"])
portfolio_quantbr = asset_sql[condition].copy()
portfolio_quantbr.rename(columns={ 'id': 'asset_id'}, inplace=True)
portfolio_quantbr.drop('symbol', axis=1, inplace = True)
portfolio_quantbr
| asset_id | |
|---|---|
| 29 | 30 |
| 50 | 51 |
| 55 | 56 |
| 62 | 63 |
| 77 | 78 |
Novamente, vamos estabelecer uma condição para isolar o ID da carteira QuantBrasil e atribuí-la à coluna portfolio_id.
portfolio_quantbr["portfolio_id"] = int(
portfolio_sql.loc[portfolio_sql["name"] == "QuantBrasil", 'id']
)
portfolio_quantbr
| asset_id | portfolio_id | |
|---|---|---|
| 29 | 30 | 2 |
| 50 | 51 | 2 |
| 55 | 56 | 2 |
| 62 | 63 | 2 |
| 77 | 78 | 2 |
Finalmente, basta juntar ambos dataframes (portfolio_ibov e portfolio_quantbr) através da função pd.concat() e voilá: nossa tabela asset_portfolio está completa!
asset_portfolio = pd.concat([portfolio_ibov, portfolio_quantbr], ignore_index=False)
asset_portfolio
| asset_id | portfolio_id | |
|---|---|---|
| 0 | 1 | 1 |
| 1 | 2 | 1 |
| 2 | 3 | 1 |
| 3 | 4 | 1 |
| 4 | 5 | 1 |
| ... | ... | ... |
| 29 | 30 | 2 |
| 50 | 51 | 2 |
| 55 | 56 | 2 |
| 62 | 63 | 2 |
| 77 | 78 | 2 |
87 rows × 2 columns
O código a seguir segue a mesma estrutura da query upsert que escrevemos anteriormente.
insert_init = """
INSERT INTO asset_portfolio (asset_id, portfolio_id)
VALUES
"""
values = ",".join(["('{}', '{}')"
.format(row["asset_id"], row["portfolio_id"])
for asset_id, row in asset_portfolio.iterrows()
])
insert_end = """
ON CONFLICT (asset_id, portfolio_id) DO UPDATE
SET
asset_id = EXCLUDED.asset_id,
portfolio_id = EXCLUDED.portfolio_id;
"""
query = insert_init + values + insert_end
engine.execute(query)Nossa tabela em SQL ficará assim (a imagem a seguir apresenta apenas as 10 primeiras linhas):
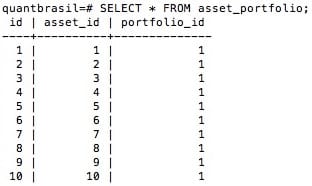
Agora que já temos todas as tabelas devidamente criadas e populadas, vamos entender como as queries de relacionamento funcionam na prática.
Escrevendo uma query de relacionamento
O comando JOIN nos permite fazer o relacionamento entre os dados das tabelas.
Esse comando baseia-se no paradigma dos conjuntos, fazendo a interseção entre os dados através das chaves primárias e estrangeiras.
Em relação à query, utilizaremos basicamente o comando SELECT para selecionar a tabela que contém a chave primária, seguido de INNER JOIN, para selecionar a tabela com a chave estrangeira relacionada. Como estamos fazendo a interseção entre 3 tabelas, precisaremos de dois comandos JOIN.
Você pode ainda especificar uma carteira empregando uma condição através do comando WHERE.
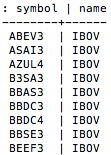
A query final é a seguinte:
'''
Run this query in your own database
SELECT asset.symbol, portfolio.name
FROM asset
INNER JOIN asset_portfolio
ON asset.id = asset_portfolio.asset_id
INNER JOIN portfolio
ON portfolio.id = asset_portfolio.portfolio_id
WHERE portfolio.name = 'IBOV';
'''
As 10 primeiras linhas do nosso output serão as seguintes:
Conclusão
No artigo de hoje vimos como qualquer um pode criar seu próprio banco de dados de maneira simples e prática. O intuito do post foi abordar o tema de forma didática, mas a área de banco de dados é um mar vasto que vale a pena ser explorado!
O foco agora é tornar nosso banco de dados ainda mais completo para que ele seja o suficiente na realização de nossas análises. Sendo assim, o próximo passo será incluir mais informações como preços de abertura, fechamento, máximas e mínimas, em diversos timeframes.
Se esse conteúdo te interessa, não deixe de se escrever na nossa newsletter e participar do nosso grupo no Telegram. Lá você não perde nenhum post!
Inscreva-se no canal do QuantBrasil!
Acompanhe novidades sobre a plataforma, vídeos sobre finanças quantitativas, tutoriais sobre programação e Inteligência Artificial!