Criando uma Base de Dados de Preços de Ativos Utilizando Python e SQL
No último artigo Como Criar Seu Próprio Banco de Dados de Ações Utilizando Python e SQL, realizamos a primeira modelagem do nosso banco de dados: criamos as tabelas asset, portfolio e uma tabela associativa asset_portfolio, que populamos com os ativos que compõem o Ibovespa.
O esquema lógico ficou assim:
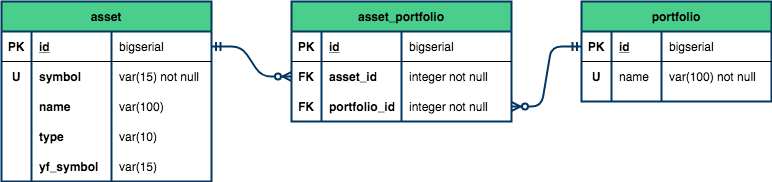
No artigo de hoje nós daremos continuidade à modelagem do banco de dados, a fim de inserir informações de preço de um determinado ativo em diversos timeframes.
Para isso, iremos seguir os mesmos passos que fizemos no último artigo:
- Identificar as tabelas necessárias;
- Determinar as colunas e os tipos de dados para cada tabela;
- Definir as restrições e os relacionamentos entre as tabelas;
- Escrever as queries com todas as informações acima.
1. Identificando as tabelas necessárias
Há dois grupos de dados principais que gostaríamos acrescentar no nosso banco de dados: os timeframes e os preços. Logo, criaremos uma tabela para cada um deles:
timeframe: o intervalo de tempo no qual a variação de preço foi observada (15 minutos, 1 dia, 1 semana, etc);price: informações, para um determinado ativo, dos preços de abertura, fechamento, máxima e mínima, além do volume, em um determinado timeframe.
Podemos observar pelo diagrama abaixo, que tanto a tabela timeframe quanto a tabela asset se relacionam com a tabela price em uma proporção de 1:n.
Se somarmos as cardinalidades, teríamos um relacionamento de muitos para muitos (N:M), o que pode nos levar a conflitos de unicidade. Resolveremos esse problema ao definirmos as restrições no passo 3.
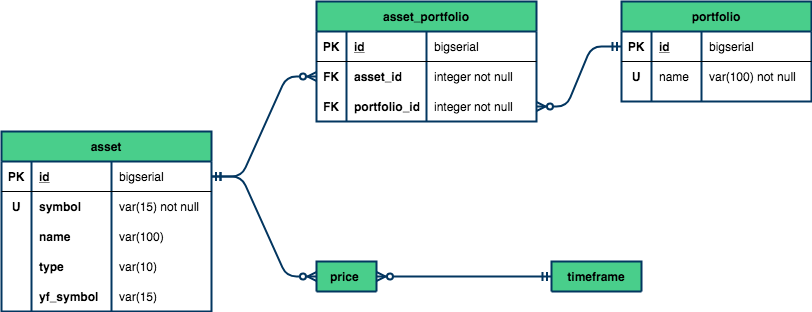
2. Determinando as colunas e os tipos de dados para cada tabela
A tabela timeframe apresentará apenas duas colunas:
| Coluna | Descrição |
|---|---|
| id | identificador único para o intervalo de tempo |
| description | descrição do intervalo de tempo |
Já a tabela price terá as seguintes colunas:
| Coluna | Descrição |
|---|---|
| id | identificador único do registro |
| asset_id | identificador único do ativo |
| timeframe_id | identificador único do timeframe |
| datetime | data e hora do início do intervalo de tempo |
| open | preço de abertura |
| high | maior valor negociado durante o intervalo de tempo |
| low | menor valor negociado durante o intervalo de tempo |
| close | preço de fechamento |
| volume | número de negócios no intervalo de tempo |
Os tipos de dados utilizados são praticamente os mesmos do post anterior, com exceção dos preços, onde utilizaremos o tipo double precision para uma maior precisão das casas decimais.
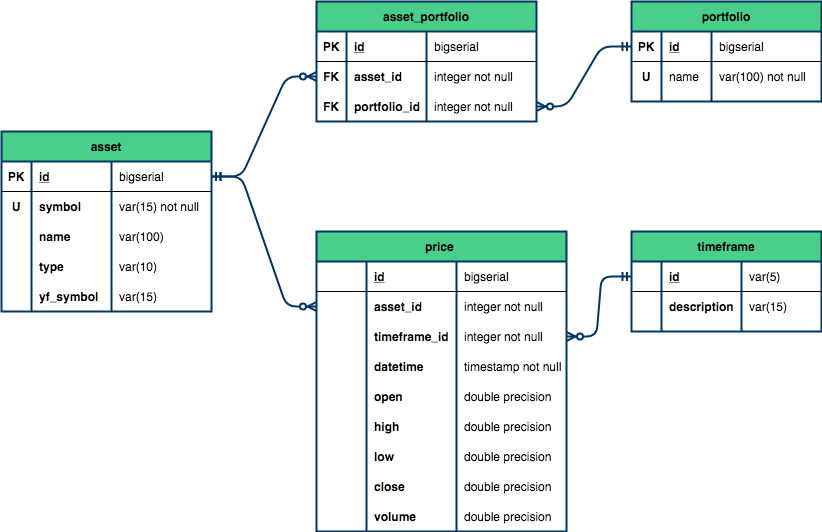
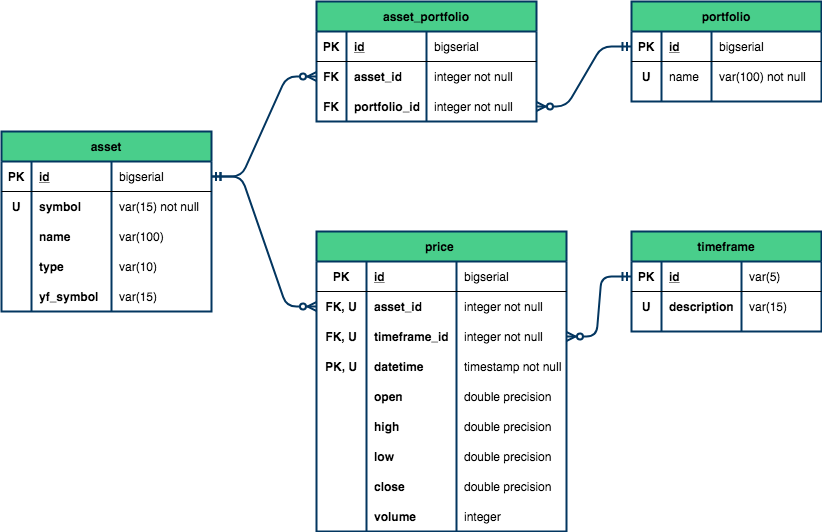
3. Definindo as restrições e os relacionamentos
A tabela timeframe terá como chave primária (PK) o id, que será também chave estrangeira (FK) na tabela price (timeframe_id). Além desta última, a tabela price terá uma segunda chave estrangeira referente aos ativos da tabela asset (asset_id).
Já como chave primária da tabela price, determinaremos a tupla id e datetime.
Por fim, para garantir a unicidade dos registros da tabela price, estabeleceremos que a combinação entre os ativos (asset_id), intervalos de tempo (timeframe_id) e datas (datetime) terá que ser única. Dessa forma, nos asseguramos de que nenhum registro será duplicado.
4. Escrevendo as queries
No primeiro artigo dessa série nós aprendemos a converter instruções Python em SQL e enviá-las ao banco de dados utilizando duas bibliotecas: SQLAlchemy e psycopg2. Portanto, o código de hoje será baseado nessa mesma dinâmica.
Para isso, precisamos instalar e importar as bibliotecas necessárias:
import pandas as pd
import numpy as np
import sqlalchemy
from sqlalchemy import create_engine
!pip install psycopg2-binary
import psycopg2Requirement already satisfied: psycopg2-binary in /opt/anaconda3/lib/python3.8/site-packages (2.8.6)
O segundo passo é estabelecer uma conexão com o banco de dados. Não se esqueça de substituir o valor das variáveis com as suas próprias credenciais.
# Replace the variables below with your own data
user_name = 'postgres'
password = 'mypwd'
host = 'localhost'
port = 5432
db_name = 'quantbrasil'
DB_ADDRESS = "postgresql://{}:{}@{}:{}/{}".format(user_name, password, host, port, db_name)
engine = create_engine(DB_ADDRESS)Com a conexão estabelecida, nós podemos escrever as queries e executá-las no banco de dados através da função execute.
Atenção: para que o código a seguir funcione, é necessário obter as tabelas do último post criadas e populadas.
Repare que nós temos que criar a tabela timeframe primeiro, uma vez que a tabela price irá referenciá-la como chave estrangeira:
# Creating timeframe table
timeframe_query = """CREATE TABLE timeframe (
id VARCHAR (5) PRIMARY KEY,
description VARCHAR (15) NOT NULL
);"""
engine.execute(timeframe_query)
# Creating price table
price_query = """CREATE TABLE price (
id BIGSERIAL,
asset_id INTEGER NOT NULL REFERENCES asset(id),
timeframe_id VARCHAR (5) NOT NULL REFERENCES timeframe(id),
datetime TIMESTAMP NOT NULL,
open DOUBLE PRECISION,
high DOUBLE PRECISION,
low DOUBLE PRECISION,
close DOUBLE PRECISION,
volume INTEGER,
PRIMARY KEY (id, datetime),
UNIQUE (asset_id, timeframe_id, datetime)
);"""
engine.execute(price_query)<sqlalchemy.engine.result.ResultProxy at 0x11abbecd0>Com as tabelas criadas, podemos começar a populá-las com os dados desejados.
Populando a tabela timeframe
A tabela timeframe será populada com alguns dos intervalos de tempos disponíveis no MetaTrader e suas respectivas descrições:
# Inserting the timeframes' name
insert_query = """
INSERT INTO timeframe (id, description)
VALUES ('M5', '5 minutes'),
('M10', '10 minutes'),
('M15', '15 minutes'),
('M30', '30 minutes'),
('H1', '1 hour'),
('H2', '1 hours'),
('H4', '4 hour'),
('D1', 'Daily'),
('W1', 'Weekly'),
('MN', 'Monthly');
"""
engine.execute(insert_query)<sqlalchemy.engine.result.ResultProxy at 0x109c5e8e0>Rodando a query SELECT * FROM timeframe; no terminal do seu banco de dados, a tabela deverá se parecer com a seguinte:
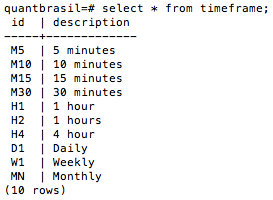
Simples, não? Agora vamos à tabela price!
Populando a tabela price
Com o intuito de escrever um código mais curto e simples, vamos assumir que você já tenha os arquivos (em formato csv) baixados do MetaTrader (ou da sua corretora) na sua máquina local. Não se preocupe, deixaremos os arquivos disponíveis no nosso canal do Telegram para que você possa reproduzir o código sem problemas.
Todavia, caso você queira testar suas habilidades de data scientist e extrair os dados do MetaTrader, nós recomendamos ambos tutoriais: em inglês e em português.
Para começar, vamos adicionar os preços de apenas um ativo em dois timeframes diferentes, 2 e 4 horas. Vamos levar em consideração que o nome do arquivo seja o ticker do ativo dentro de uma pasta nomeada com o id do timeframe, ou seja, H2 e H4 respectivamente.
Veja pela figura a seguir:

Dessa forma, o objetivo do nosso código é iterar sobre cada pasta de timeframes e, uma vez dentro dessas pastas, iterar sobre cada arquivo csv presente nelas. Assim, seremos capazes de ler cada um desses arquivos em um dataframe e, por fim, inseri-los no banco de dados.
Para simplificar, vamos escrever uma função populate_price para realizar esse último passo: ler um arquivo em um dataframe e escrever a query de inserção.
A função receberá três argumentos:
symbol: o ticker do ativo;timeframe: o id do intervalo de tempo em que os dados se encontram;path: o caminho (da sua máquina local) até as pastas de timeframes.
E executará os seguintes passos:
- Ler o arquivo em um dataframe;
- Importar os
idsreferentes ao ativo e ao timeframe das respectivas tabelas do PostgreSQL; - Caso o ativo que esteja sendo inserido não exista na tabela
asset(len(asset_i)==0), a função irá inseri-lo; - Por fim, a função retorna a query de inserção dos dados pronta para ser executada.
def populate_price(symbol, timeframe, path):
df = pd.read_csv(f"{path}/{timeframe}/{symbol}.csv")[[
"time","open", "high", "low", "close", "real_volume"
]]
df.rename(columns={"time": "datetime", "real_volume": "volume"}, inplace=True)
# Importing asset_id and timeframe_id from tables in PostgreSQL
asset_id = pd.read_sql(f"SELECT id FROM asset WHERE symbol = '{symbol}';", engine)
# Insert into table if asset does not exist
if len(asset_id) == 0:
query = f"INSERT INTO asset (symbol) VALUES ('{symbol}');"
engine.execute(query)
asset_id = pd.read_sql(f"SELECT id FROM asset WHERE symbol = '{symbol}';", engine)
# Creating the columns
df["asset_id"] = int(asset_id["id"])
df["timeframe_id"] = timeframe
# Writing the SQL query to populate price table
insert_init = """
INSERT INTO price (datetime, open, high, low, close, volume, asset_id, timeframe_id)
VALUES
"""
values = ",".join(
[
"('{}', '{}', '{}', '{}', '{}', '{}', '{}', '{}')".format(
row["datetime"],
row["open"],
row["high"],
row["low"],
row["close"],
row["volume"],
row["asset_id"],
row["timeframe_id"]
)
for datetime, row in df.iterrows()
]
)
insert_end = """
ON CONFLICT (datetime, asset_id, timeframe_id)
DO UPDATE SET
open = EXCLUDED.open,
high = EXCLUDED.high,
low = EXCLUDED.low,
close = EXCLUDED.close,
volume = EXCLUDED.volume;
"""
query = insert_init + values + insert_end
return queryCom a função pronta, os próximos passos são:
- Iterar sobre as pastas de timeframes;
- Isolar o ticker referente ao arquivo (basta remover o sufixo
.csv); - Chamar a função
populate_price, que nada mais é do que nossa query de inserção; - Executar a query.
Para isso, precisamos importar as bibliotecas os e glob que nos possibilitam manipular os diretórios (pastas) da nossa máquina.
Através da função os.listdir nós somos capazes de listar todos os diretórios presentes no endereço que passamos como argumento e, portanto, iterar sobre eles.
OBS: Caso você esteja trabalhando em um Mac OS X, todos os diretórios possuem um arquivo '.DS_Store' que é criado automaticamente pelo Finder e contém informações sobre as configurações do sistema. Para não gerar nenhum erro no nosso código, vamos remover esse arquivo da nossa lista se ele existir. Feito isso, temos que iterar novamente sobre a lista atualizada de diretórios.
A função os.chdir nos possibilita trocar de diretório para o endereço passado como argumento. Uma vez dentro da pasta do timeframe em questão, nós listaremos todos (representado por *) os arquivos em formato csv daquela pasta através da função glob.
Por fim, removeremos o sufixo .csv do nome dos arquivos, a fim de obter apenas o símbolo que será utilizado na função populate_price.
import os
import glob
# Replace path with your own
path = "../../data"
# Looping through all the timeframes directories
timeframe_dirs = os.listdir(path)
for timeframe in timeframe_dirs:
# Ignores '.DS_Store' in case the script is running in a mac computer
if timeframe != ".DS_Store":
os.chdir(f"{path}/{timeframe}")
assets_files = glob.glob("*.csv")
symbol_list = [s[:-4] for s in assets_files]
for symbol in symbol_list:
query = populate_price(symbol, timeframe, path)
engine.execute(query)
print("Data Inserted Successfully")
Data Inserted Succesfully
Data Inserted Succesfully
Nossa tabela price ficou assim:
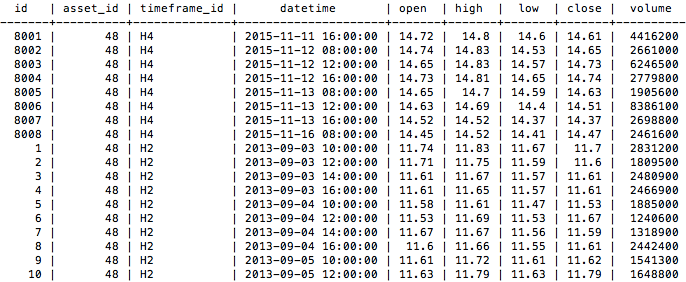
Conclusão
Com nosso banco de dados contendo informações de preços em diversos timeframes e, o mais importante, de uma fonta de dados confiável, somos capazes de realizar qualquer backtest sem depender de fontes externas.
Como falamos no artigo anterior, a vantagem de possuir seu próprio banco de dados é obter os dados de forma estruturada de acesso ilimitado e rápido. Além disso, você é livre para armazenar as informações que quiser e realizar suas próprias análises, fundamentalistas ou técnicas.
Nos próximos posts iremos aprender como extrair e manipular os dados do MetaTrader, além de incluir outros portfólios (como as BDRs) ao nosso banco de dados, através de web scraping.
Não deixe de se inscrever na nossa newsletter e de participar do nosso grupo do Telegram para ter acesso aos posts em primeira mão e muito mais!
Inscreva-se no canal do QuantBrasil!
Acompanhe novidades sobre a plataforma, vídeos sobre finanças quantitativas, tutoriais sobre programação e Inteligência Artificial!