Como Exportar Dados do ProfitChart para um Banco de Dados Utilizando Python e SQL
No último tutorial de banco de dados, nós modelamos e populamos a tabela price a partir de arquivos csv exportados da plataforma MetaTrader.
No artigo de hoje aprenderemos a exportar os preço de uma segunda fonte de dados, muito utilizada no universo do trader: a plataforma de negociações ProfitChart, além de inserir esses dados no banco de dados.
Para acompanhar na prática o tutorial, é preciso que você tenha o banco de dados modelado e montado na sua máquina local. Caso você ainda não tenha, comece por esse post. Para quem já tem o banco de dados rodando: mãos a obra!
Exportando dados do ProfitChart
O primeiro passo é exportar os arquivos diretamente da sua plataforma do Profit. É bem simples, basta realizar os seguintes passos:
- Clicar em Arquivo > Exportar CSV:
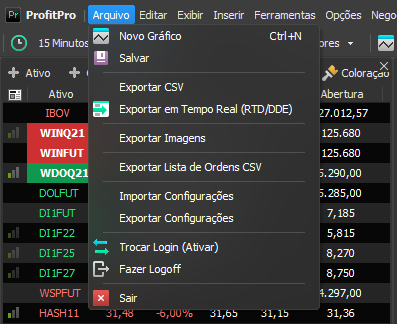
- Selecionar o diretório (pasta) de exportação, os ativos e marcar "Aplicar formatação dos dados":
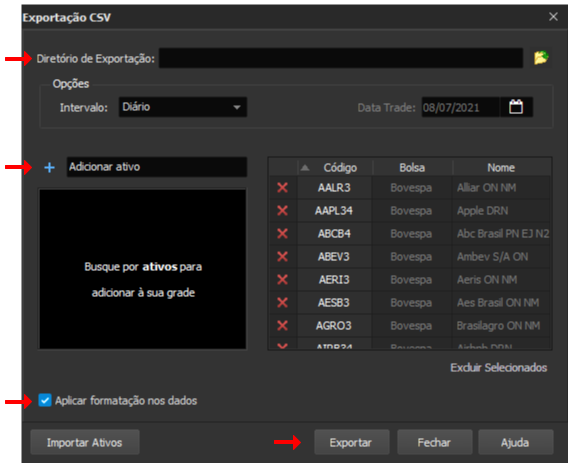
OBS.: o campo "Aplicar formatação dos dados" é importante para que o arquivo tenha a Data, Abertura, Fechamento, Máximo e Mínimo como colunas.
- Clicar em "Exportar":
Infelizmente o Profit nos permite baixar apenas os preços de 2 anos, mas esse período já nos fornece uma boa base de dados para se trabalhar.
OBS: Verifique se a sua versão do Profit suporta exportação de dados.
Assim como foi feito no último artigo, exportaremos os arquivos separados em pastas por timeframe (o nome da pasta tem que ser exatamente igual ao timeframe_id utilizado no banco de dados), como na imagem a seguir:
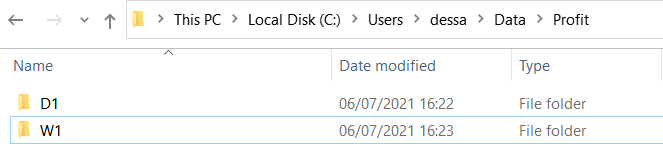
Da mesma maneira, o objetivo será iterar sobre cada uma dessas pastas separadas por timeframe. Uma vez dentro delas, iremos iterar sobre os arquivos, parseá-los em um dataframe e inseri-los no banco de dados.
Com os arquivos baixados, podemos ir para a segunda (e mais legal) parte do post: o código!
Inserindo os dados no banco de dados
Para uma melhor didática, vamos dividir nosso código em 3 etapas:
- Importar as bibliotecas necessárias;
- Estabelecer uma conexão com o banco de dados;
- Iterar sobre cada arquivo exportado a fim de inseri-los no banco de dados.
O último passo (um bloco extenso de código) será dividido em 5 partes para que você entenda cada pedacinho dele.
Importanto as bibliotecas necessárias
As bibliotecas a seguir são as mesmas utilizadas no último tutorial:
- pandas: nos possibilitará ler os arquivos em dataframe e tratar os dados;
- glob e os: essenciais para manipular os diretórios (pastas) e seus respectivos arquivos na máquina local;
- sqlalchemy e psycopg2: necessárias para converter instruções Python em SQL e enviá-las ao banco de dados.
# %%capture means we suppress the output
%%capture
import pandas as pd
# Library to manipulate directories
import glob
import os
# Library to connect and convert python to sql
from sqlalchemy import create_engine
!pip install psycopg2-binary
import psycopg2Estabelecendo uma conexão com o banco de dados
Crie uma conexão com o banco de dados substitutindo as variáveis a seguir com suas próprias credenciais:
# Replace the variables below with your own data
user_name = 'postgres'
password = 'mypwd'
host = 'localhost'
port = 5432
db_name = 'quantbrasil'
DB_ADDRESS = "postgresql://{}:{}@{}:{}/{}".format(user_name, password, host, port, db_name)
engine = create_engine(DB_ADDRESS)Iterando sobre cada arquivo exportado e inserindo-os no banco de dados
No último artigo nós criamos uma função para popular a tabela price e simplificar o código. No entanto, não será possível reaproveitar tal função, uma vez que precisaremos fazer algumas manipulações nos dados obtidos pelo Profit.
Por conta disso, o código será todo escrito dentro do for loop que irá iterar sobre cada diretório de timeframe, possibilitando assim realizar os tratamentos necessários.
Como mencionado, dividiremos essa última etapa em 5 partes:
Parte 1: Iterando sobre os diretórios de cada timeframe (no caso, D1 e W1);
Parte 2: Iterando sobre cada arquivo do diretório;
Parte 3: Manipulando a coluna de data e hora;
Parte 4: Selecionando o id do ativo;
Parte 5: Escrevendo a query em SQL para popular a tabela price;
O código completo pode ser visto abaixo. Após, explicaremos cada parte individualmente.
# Part 1: Looping through each timeframe's directories
# Replace with your own
path = "/../../Data/Profit"
timeframe_dirs = os.listdir(f"{path}")
for timeframe in timeframe_dirs:
timeframe_dirs_path = f"{path}/{timeframe}"
os.chdir(timeframe_dirs_path)
files = glob.glob("*.csv")
print("Lista dos arquivos salvos no diretório: ", files)
# Part 2: Looping through all files in the timeframe's directory
for file in files:
symbol = file.split("_")[0]
if "FUT" in symbol:
symbol = symbol.replace("FUT", "$")
df = pd.read_csv(f"{path}/{timeframe}/{file}",
sep=";",
encoding="latin-1",
thousands=".",
decimal=",",
header=0)[[
"Data", "Abertura", "Máximo", "Mínimo",
"Fechamento", "Volume"
]]
# Part 3: Manipulating datetime column
df["Data"] = pd.to_datetime(df["Data"], format="%d/%m/%Y")
if timeframe == 'W1':
df["Data"] = df["Data"] - pd.Timedelta(days=1)
# Part 4: Getting asset's id
get_id_query = f"""
SELECT id
FROM asset
WHERE asset.symbol = '{symbol}';
"""
result = engine.execute(get_id_query).fetchone()
if (result is None):
print(f"Asset {symbol} not found in DB, creating...")
insert_asset_query = f"""
INSERT INTO asset (symbol)
VALUES ('{symbol}')
ON CONFLICT (symbol)
DO NOTHING
RETURNING id;
"""
asset_id = engine.execute(insert_asset_query).fetchone()[0]
else:
asset_id = result[0]
# Part 5: Writing the SQL query to (re)populate price table
insert_init = """
INSERT INTO price (datetime, open, high, low, close, volume, asset_id, timeframe_id)
VALUES
"""
values = ",".join([
"('{}', '{}', '{}', '{}', '{}', '{}', '{}', '{}')".format(
row["Data"],
float(row["Abertura"]),
float(row["Máximo"]),
float(row["Mínimo"]),
float(row["Fechamento"]),
int(row["Volume"]),
asset_id,
timeframe) for datetime, row in df.iterrows()
])
insert_end = """
ON CONFLICT (datetime, asset_id, timeframe_id)
DO UPDATE SET
open = EXCLUDED.open,
high = EXCLUDED.high,
low = EXCLUDED.low,
close = EXCLUDED.close,
volume = EXCLUDED.volume;
"""
print(f"Inserted all from {symbol} in {timeframe}")
query = insert_init + values + insert_end
engine.execute(query)Lista dos arquivos salvos no diretório: ['ARZZ3_B_0_Diário.csv', 'CIEL3_B_0_Diário.csv', 'COGN3_B_0_Diário.csv', 'DOLFUT_F_0_Diário.csv', 'WINFUT_F_0_Diário.csv']
Asset ARZZ3 not found in DB, creating...
Inserted all from ARZZ3 in D1
Inserted all from CIEL3 in D1
Inserted all from COGN3 in D1
Asset DOL$ not found in DB, creating...
Inserted all from DOL$ in D1
Inserted all from WIN$ in D1
Lista dos arquivos salvos no diretório: ['ARZZ3_B_0_Semanal.csv', 'CIEL3_B_0_Semanal.csv', 'COGN3_B_0_Semanal.csv', 'DOLFUT_F_0_Semanal.csv', 'VALE3_B_0_Semanal.csv', 'WINFUT_F_0_Semanal.csv']
Inserted all from ARZZ3 in W1
Inserted all from CIEL3 in W1
Inserted all from COGN3 in W1
Inserted all from DOL$ in W1
Inserted all from VALE3 in W1
Inserted all from WIN$ in W1
Parte 1: Iterando sobre os diretórios de cada timeframe
O primeiro passo é definir a variável path: endereço na sua máquina local para o diretório principal Profit demonstrado anteriormente. Nele se encontram os diretórios separados por timeframe com os arquivos salvos.
Listaremos esses diretórios (timeframe_dirs) utilizando o método listdir e iteraremos sobre eles. Em seguida, através do método chdir, entraremos em cada um desses diretórios (timeframe_dirs_path).
Uma vez dentro dessas pastas, listaremos todos os arquivos em csv (files) presentes utilizando o método glob, para finalmente iterar sobre cada um deles.
Parte 2: Iterando sobre cada arquivo do diretório
Quando um arquivo é exportado do Profit, ele é automaticamente salvo no seguinte padrão: PETR4_B_Diário ou PETR4_B_Semanal para ativos no mercado à vista, e WINFUT_F_Diário ou WINFUT_F_Semanal para contratos futuros.
Para isolarmos somente o símbolo de cada ativo, utilizaremos a função split, que divide strings em torno de um delimitador fornecido (no nosso caso, o underline). A função retorna então uma lista com as strings separadas, na qual o primeiro item será o símbolo (symbol) do ativo.
Os ativos do mercado futuro exportados pelo MetaTrader apresentam um cifrão no símbolo (DOL$, por exemplo) diferente da nomenclatura utilizada pelo Profit (DOLFUT). Por conta disso, para quem já possui esses dados com a nomenclatura do MetaTrader, é preciso substituir a substring "FUT" por $ para evitar dados duplicados. Isso é facilmente feito utilizando a função replace.
Por fim, converteremos os arquivos em csv para dataframes através da função read_csv do pandas.
Parte 3: Manipulando a coluna de data e hora
Antes de prosseguir, experimente dar um print utilizando o atributo dtype no seu dataframe. Você verá que as coluna são do tipo 'object'. Isso pode nos gerar erros ao tentar inseri-los no banco de dados, uma vez que nele cada coluna contém seu tipo de dado específico.
Vamos, portanto, começar alterando a coluna Data para o tipo datetime correto, através da função to_datetime. Não se esqueça de passar o formato em que a data se encontra como argumento (format).
Será necessário fazer outro tratamento na coluna Data para quem já possui dados de preço extraídos do MetaTrader: os dados semanais dessa plataforma começam no domingo, enquanto que no Profit começam na segunda-feira. Levando em consideração que ativos como criptomoedas, por exemplo, são negociados de domingo a domingo e a semana de fato começa no domingo, vamos considerá-lo o mais correto.
Dessa forma, se o timeframe for igual a W1 (semanal), diminuiremos um dia da coluna Data através da função Timedelta.
Em relação às demais colunas, alteraremos o seu tipo quando formos inseri-las ao banco de dados.
Parte 4: Selecionando o id do ativo
Com nosso dataframe devidamente tratado, o id do ativo é a última informação que nos falta para popular a tabela price.
Importaremos o id utilizando apenas as funções execute e fetchone combinadas para executar a query (get_id_query) e retornar o seu resultado (result). Extrair informações de um banco de dados dessa maneira é mais eficiente do que utilizar a função read_csv.
Incluiremos uma condição caso o ativo não exista no banco de dados: se result for None, inseriremos o ativo na tabela asset através da query insert_asset_query, retornando também seu id. Caso contrário, selecionaremos o primeiro valor do retornado por result (a função fetchone retorna uma tupla, por isso temos que especificar o primeiro valor [0]).
Agora que já isolamos o id do ativo, podemos escrever a query e executá-la no banco de dados.
Parte 5: Escrevendo a query em SQL para popular a tabela price
A query será escrita da mesma maneira que nos últimos artigos. Alguns pontos importantes que não podemos esquecer:
- as colunas devem estar na mesma ordem dos respectivos valores;
- temos que especificar o tipo de dado das colunas restantes: o volume será um número inteiro (
int) e as demais - Máximo, Mínimo, Abertura e Fechamendo - em decimal (float); - o final da query (
insert_end) cobre o caso onde os dados já existem, atualizando-os apropriadamente.
Pronto! Basta executar a query e a nova base de dados será inserida com sucesso.
Conclusão
Chegamos ao final de mais um artigo da série sobre banco de dados utilizando Python e SQL.
Hoje nós aprendemos a extrair dados de uma nova fonte: a plataforma de negociações ProfitChart. Essa é uma excelente fonte de dados para você estudar e testar os diversos backtests aqui disponíveis.
Não esqueça de se inscrever na nossa newsletter e participar do grupo no Telegram para receber as novidades do QuantBrasil em primeira mão!
Inscreva-se no canal do QuantBrasil!
Acompanhe novidades sobre a plataforma, vídeos sobre finanças quantitativas, tutoriais sobre programação e Inteligência Artificial!