Baixando Cotações e Plotando Médias Móveis com Python
Jupyter Notebooks permitem que análises de Data Science sejam feitas de forma dinâmica e colaborativa. Aliados com o poder do pandas para manipulação de dados em grandes quantidades, e matplotlib para rápida e fácil visualização, Notebooks são a ferramenta ideal para quem deseja fazer suas próprias análises.
O objetivo do QuantBrasil é compartilhar essas análises, aprendendo e ensinando sobre mercado financeiro e programação durante o processo. Mesmo que você não seja familiar com a tecnologia, fique por aqui! Queremos ser didáticos o suficiente para engajar pessoas com pouco ou nenhum conhecimento técnico, e ainda assim trazer valor com nossas análises mesmo que você seja experiente com análise quantitativa ou programação em Python.
Nota sobre Notebooks
Os posts desse blog são, eles mesmos, Jupyter Notebooks. Todo o código fonte pode ser acessado diretamente no Github. A forma mais simples de reproduzir o que é discutido nesses posts é através do Google Colab, um ambiente Jupyter online, onde você pode rodar suas análises sem precisar baixar nada.
No entanto, para projetos mais completas ou para mais performance, recomendamos a instalação de um ambiente local. Uma sugestão para quem deseja mais recursos é a instalação do Anaconda, que, além do Jupyter, também conta com várias outras ferramentas para Data Science.
Esqueleto de uma Análise
A maior parte dos nossos artigos será composto por três partes:
- Aquisição de dados
- Manipulação de dados
- Análise e/ou Apresentação de resultados
O primeiro post desse site unirá o básico dos 3 — aprenderemos a baixar cotações das empresas via Yahoo Finance e plotaremos as primeiras médias móveis.
1. Aquisição de Dados
Existem várias formas de se conseguir as cotações históricas dos papeis. A melhor, claro, vai depender do contexto e de sua necessidade. A forma mais fácil é através da API do Yahoo Finance, que permite baixar os dados com bastante confiança e de forma muito rápida.
O primeiro passo é instalar a biblioteca:
# %%capture means we suppress the output
%%capture
!pip install yfinance
import yfinance as yfCom a biblioteca instalada, baixar os dados é tão simples quanto:
data = yf.download("VALE3.SA", start="2019-01-01", end="2019-12-31")
data
| Open | High | Low | Close | Adj Close | Volume | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 2019-01-02 | 50.009998 | 51.369999 | 49.790001 | 51.090000 | 47.774075 | 17319600 |
| 2019-01-03 | 50.799999 | 50.939999 | 48.400002 | 49.000000 | 45.819725 | 30120000 |
| 2019-01-04 | 49.820000 | 52.450001 | 49.820000 | 52.189999 | 48.802681 | 43360100 |
| 2019-01-07 | 52.869999 | 53.650002 | 51.720001 | 51.910000 | 48.540855 | 20998900 |
| 2019-01-08 | 52.200001 | 52.799999 | 51.619999 | 52.410000 | 49.008404 | 19925600 |
| ... | ... | ... | ... | ... | ... | ... |
| 2019-12-20 | 54.770000 | 54.990002 | 54.150002 | 54.790001 | 51.233932 | 42124200 |
| 2019-12-23 | 54.900002 | 54.980000 | 54.400002 | 54.580002 | 51.037563 | 10225700 |
| 2019-12-26 | 54.810001 | 55.000000 | 54.509998 | 54.790001 | 51.233932 | 20410000 |
| 2019-12-27 | 53.990002 | 54.000000 | 53.419998 | 53.599998 | 51.449287 | 13920400 |
| 2019-12-30 | 53.650002 | 53.860001 | 53.200001 | 53.299999 | 51.161327 | 11928100 |
247 rows × 6 columns
Pronto! Nós baixamos as cotações da VALE3 do ano de 2019 e armazenamos numa estrutura chamada dataframe. Um dataframe é uma espécie de tabela que permite acesso e manipulação das linhas e colunas de forma eficiente (vetorial), tornando-se ideal para análises de datasets muito grandes.
Caso nosso interesse seja apenas no valor de fechamento, nós podemos acessar colunas específicas do nosso dataframe:
all_closes = data["Adj Close"]
print(all_closes)Date 2019-01-02 47.774075 2019-01-03 45.819725 2019-01-04 48.802681 2019-01-07 48.540855 2019-01-08 49.008404 ... 2019-12-20 51.233932 2019-12-23 51.037563 2019-12-26 51.233932 2019-12-27 51.449287 2019-12-30 51.161327 Name: Adj Close, Length: 247, dtype: float64
Repare que quando selecionamos apenas uma coluna, o retorno é uma instância da classe Series. Series são fundamentalmente diferentes de dataframes — elas podem ser entendidas como vetores unidimensionais. Explorar a diferença entre dataframes e series está além do escopo deste post, mas é importante entender que nem todos os métodos que aplicam-se a um, funcionará no outro.
Caso você deseje explicitamente manipular um dataframe de apenas uma coluna, uma alternativa possível é a seguinte:
df = data[["Adj Close"]]
df
| Adj Close | |
|---|---|
| Date | |
| 2019-01-02 | 47.774075 |
| 2019-01-03 | 45.819725 |
| 2019-01-04 | 48.802681 |
| 2019-01-07 | 48.540855 |
| 2019-01-08 | 49.008404 |
| ... | ... |
| 2019-12-20 | 51.233932 |
| 2019-12-23 | 51.037563 |
| 2019-12-26 | 51.233932 |
| 2019-12-27 | 51.449287 |
| 2019-12-30 | 51.161327 |
247 rows × 1 columns
2. Manipulação de Dados
De posse do nosso dataset, o próximo passo é manipular os dados de acordo com a análise desejada. Nesse post introdutório, iremos calcular duas médias móveis — uma aritmética e outra exponencial.
Usando nosso dataset reduzido, vamos calcular a média móvel de 21 períodos:
df['MM21'] = df["Adj Close"].rolling(21).mean()
df
| Adj Close | MM21 | |
|---|---|---|
| Date | ||
| 2019-01-02 | 47.774075 | NaN |
| 2019-01-03 | 45.819725 | NaN |
| 2019-01-04 | 48.802681 | NaN |
| 2019-01-07 | 48.540855 | NaN |
| 2019-01-08 | 49.008404 | NaN |
| ... | ... | ... |
| 2019-12-20 | 51.233932 | 48.456697 |
| 2019-12-23 | 51.037563 | 48.659301 |
| 2019-12-26 | 51.233932 | 48.834298 |
| 2019-12-27 | 51.449287 | 49.003519 |
| 2019-12-30 | 51.161327 | 49.187526 |
247 rows × 2 columns
Simples, não? O método rolling do dataframe retorna uma janela de período n (21 no nosso exemplo). O método mean() é utilizado para computar a média da janela.
Note que os primeiros valores do nosso dataframe são NaN, ou seja, nulos. Isso é esperado, uma vez que para o primeiro valor de média de n períodos só será possível ser calculado uma vez que haja n linhas. Podemos verificar isso analisando as primeiras 21 linhas do nosso dataframe:
df.head(21)| Adj Close | MM21 | |
|---|---|---|
| Date | ||
| 2019-01-02 | 47.774075 | NaN |
| 2019-01-03 | 45.819725 | NaN |
| 2019-01-04 | 48.802681 | NaN |
| 2019-01-07 | 48.540855 | NaN |
| 2019-01-08 | 49.008404 | NaN |
| 2019-01-09 | 50.205326 | NaN |
| 2019-01-10 | 49.653622 | NaN |
| 2019-01-11 | 48.980354 | NaN |
| 2019-01-14 | 49.186069 | NaN |
| 2019-01-15 | 48.952297 | NaN |
| 2019-01-16 | 49.232830 | NaN |
| 2019-01-17 | 50.710278 | NaN |
| 2019-01-18 | 51.205879 | NaN |
| 2019-01-21 | 51.692131 | NaN |
| 2019-01-22 | 51.505112 | NaN |
| 2019-01-23 | 52.038120 | NaN |
| 2019-01-24 | 52.505665 | NaN |
| 2019-01-28 | 39.610687 | NaN |
| 2019-01-29 | 39.966022 | NaN |
| 2019-01-30 | 43.575493 | NaN |
| 2019-01-31 | 42.546886 | 48.167262 |
O cálculo da média exponencial é ligeiramente diferente, mas não menos simples:
df["MME9"] = df["Adj Close"].ewm(span=9, min_periods=9).mean()
df
| Adj Close | MM21 | MME9 | |
|---|---|---|---|
| Date | |||
| 2019-01-02 | 47.774075 | NaN | NaN |
| 2019-01-03 | 45.819725 | NaN | NaN |
| 2019-01-04 | 48.802681 | NaN | NaN |
| 2019-01-07 | 48.540855 | NaN | NaN |
| 2019-01-08 | 49.008404 | NaN | NaN |
| ... | ... | ... | ... |
| 2019-12-20 | 51.233932 | 48.456697 | 49.832455 |
| 2019-12-23 | 51.037563 | 48.659301 | 50.073477 |
| 2019-12-26 | 51.233932 | 48.834298 | 50.305568 |
| 2019-12-27 | 51.449287 | 49.003519 | 50.534312 |
| 2019-12-30 | 51.161327 | 49.187526 | 50.659715 |
247 rows × 3 columns
Dessa vez nós usamos o método ewm, ou Exponential Weighted Functions. Repare que, ao contrário de rolling, dessa vez nós precisamos explicatamente passar o tamanho da janela (span) e a quantidade mínima de dados até iniciarmos a computação (min_periods).
df.head(9)| Adj Close | MM21 | MME9 | |
|---|---|---|---|
| Date | |||
| 2019-01-02 | 47.774075 | NaN | NaN |
| 2019-01-03 | 45.819725 | NaN | NaN |
| 2019-01-04 | 48.802681 | NaN | NaN |
| 2019-01-07 | 48.540855 | NaN | NaN |
| 2019-01-08 | 49.008404 | NaN | NaN |
| 2019-01-09 | 50.205326 | NaN | NaN |
| 2019-01-10 | 49.653622 | NaN | NaN |
| 2019-01-11 | 48.980354 | NaN | NaN |
| 2019-01-14 | 49.186069 | NaN | 49.031055 |
3. Apresentação de Resultados
Nossa simples manipulação de dados está pronta, o que significa que a etapa final da análise é apresentar os resultados. Hoje, iremos simplesmente explicar como fazer uma rápida plotagem dos dados, de forma a simplificar a visualização.
A ferramenta mais comumente utilizada se chama matplotlib, uma robusta biblioteca de visualização gráfica para Python. Hora de importar a biblioteca e plotar o nosso primeiro gráfico:
import matplotlib.pyplot as plt
df["Adj Close"].plot()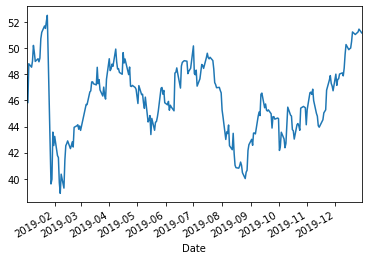
E nada mais! Com apenas uma linha de código conseguimos plotar uma coluna do nosso dataframe como um gráfico de linha. E se quisermos adicionar mais linhas?
df[["Adj Close", "MME9", "MM21"]].plot()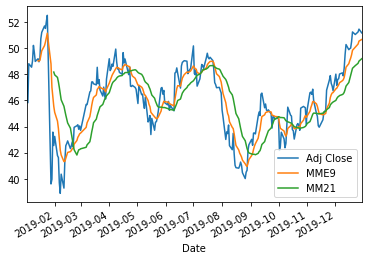
Novamente simples, como o esperado. Passando um array de colunas ["Adj Close", "MME9", "MM21"] somos capazes de, em uma linha, plotar os 3 valores e automaticamente adicionar uma legenda.
Melhorando a Apresentação do Gráfico
O último ponto que cobriremos nesse post introdutório é como melhorar a visualização do gráfico. Afinal, uma visualização de dados bem-feita precisa ser intuitiva para o leitor.
Para isso, vamos usar cores diferentes para cada linha, além de aumentarmos sua espessura e o tamanho da imagem:
plt.figure(figsize=(16,8))
plt.plot(df["Adj Close"])
plt.plot(df["MM21"], color="green", lineWidth=3)
plt.plot(df["MME9"], color="magenta", lineWidth=3)
plt.legend(df)
plt.show()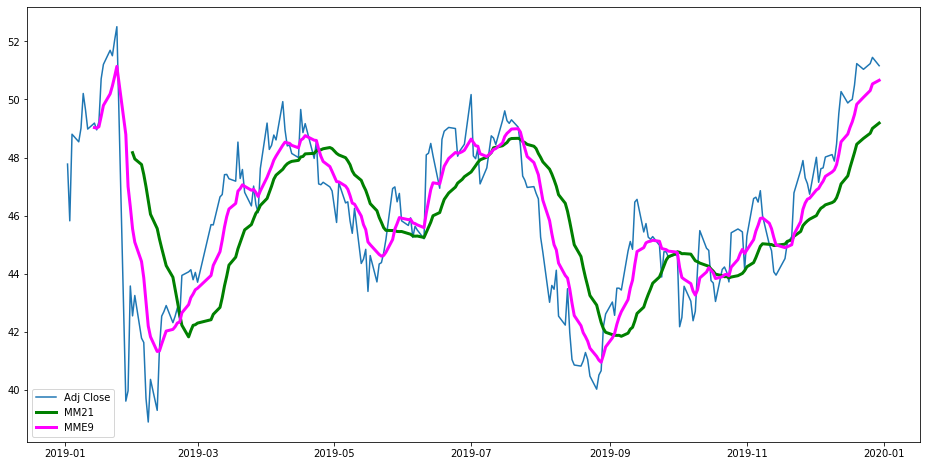
Embora pareça mais complicado, todas as linhas são bastante diretas. Vamos explicá-las uma a uma:
plt.figsizedetermina o tamanho da imagem em polegadas. Nesse caso, nossa figura será 16"x8";plt.plot, separadamente, permite que você customize a linha que está sendo plotada. Embora não façamos nenhuma mudança na linha inicial, repare que alteramos a cor e a espessura das médias;plt.legendpermite que você tenha mais controle sobre a legenda do gráfico;- Finalmente,
plot.showfinaliza a customização e exibe a imagem.
Conclusão
Análises quantitativas são uma ferramenta muito poderosa para qualquer projeto de Data Science. Em particular, no mundo do mercado financeiro, elas podem literalmente lhe custar ou gerar dinheiro. Hoje apresentamos a base do que utilizaremos para fazer análises mais complexas no futuro. Espero que o conteúdo tenha sido relevante e que de certa forma seja um incentivo para que você inicie seus estudos na área!
Inscreva-se no canal do QuantBrasil!
Acompanhe novidades sobre a plataforma, vídeos sobre finanças quantitativas, tutoriais sobre programação e Inteligência Artificial!